3000 Agents are Running Experiments in the Dark
How the NM framework is performing on Karpathy's autoresearch factory

I’ve been trying to think about how Nervous Machine can help communities quickly aggregate value through distributed channels and lower cost barriers.
The answer came through in Karpathy’s autoresearch repo.
This repo enables AI researchers to participate in step-change research quickly and iteratively on 1 GPU. It’s a relatively inclusive community, which I love...you don’t need an H100 cluster or a research lab. You need one GPU, one file, and five minutes. The agent runs experiments while you sleep. Anyone can contribute.
However, users forking the repo 3,300 times without backpropagating findings limits the community’s networking strength to deliver aggregated value. Every fork generates discoveries. None of them flow back. The confirmations go unnoticed. The contradictions go undetected. The community produces enormous amounts of evidence and learns almost nothing from it collectively.
That’s where I decided to apply Nervous Machine.
The problem is familiar
Karpathy himself named it. In his README: “The downside is that your runs become not comparable to other people running on other compute platforms.” He followed up on X, saying the next step for autoresearch needed to be “asynchronously massively collaborative for agents (think: SETI@home style)” — and that “Git(Hub) is almost but not really suited for this.”
He’s right. Git tracks what was done. It doesn’t track what was learned. A commit says “I changed line 47 of train.py.” What the community actually needs to know is: “Batch halving is the single most robust finding across all platforms, and RoPE base frequency is not what we thought it was.”
That’s a fundamentally different unit of knowledge than a code diff.
So we built the connective layer
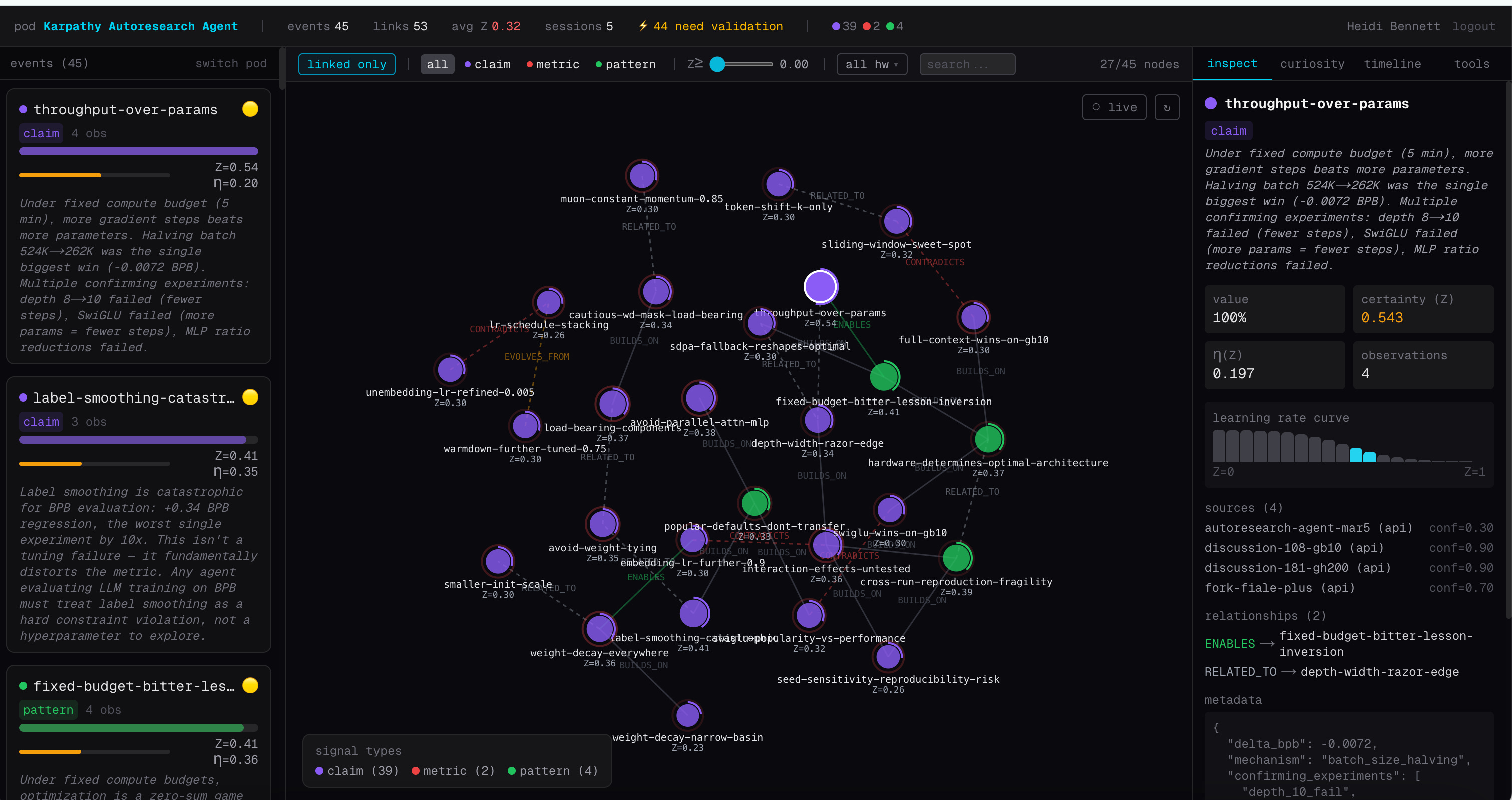
Over the past few days, we encoded hundreds of autoresearch experiment runs across H100, GB10 Blackwell, and GH200 480GB into a shared graph prior. Each finding carries a certainty score that rises when independent runs confirm it and drops when they contradict it. Here’s what happened when evidence started flowing across sessions.
The findings sorted themselves
Some climbed. Others collapsed.
Climbing: batch halving was the single biggest win in every session on every platform. Its certainty rose from 0.30 to 0.517, the highest in the graph. Label smoothing was catastrophic everywhere. Weight tying broke everywhere. Value embeddings were load-bearing everywhere. These are becoming universal truths; strategies that transfer regardless of hardware.
Collapsing: RoPE base frequency was supposed to be 200K. Three H100 runs agreed. Then the GH200 found 25K optimal. Certainty dropped to 0.167. SwiGLU showed zero improvement on H100 but actually won on GB10 Blackwell. Weight decay sweet spot, warmdown fraction, model width all shifted between platforms.
The community had been treating these as settled findings. The graph says they’re hardware-specific accidents that looked universal because everyone was running on the same GPU.
The first real contradiction
The SwiGLU finding is the one that makes the case.
On H100, SwiGLU showed zero improvement. More parameters meant fewer gradient steps in the 5-minute budget, and the quality gain didn’t offset the throughput cost. The community treated this as settled: SwiGLU doesn’t work at this scale.
Then the GB10 Blackwell data came in. SwiGLU won. The SDPA attention bottleneck on that hardware changed the throughput-quality tradeoff entirely.
In a flat experiment log, this looks like someone got a different result. In the graph, it’s a first-class contradiction; a CONTRADICTS link between two claims, each with its own certainty score and hardware context. The graph doesn’t force resolution. It holds the contradiction as the most valuable signal in the system, because it marks the exact boundary where a “universal” finding turns out to be hardware-specific.
That boundary is where the real knowledge lives.
The average certainty dropped. That’s the point.
After four sessions, the average certainty actually went down from 0.34 to 0.315. The GH200 contradictions dragged it down.
This is correct behavior. A system that only goes up isn’t learning. It’s confirming biases.
The learning function uses an adaptive rate: low certainty means learn fast, high certainty means resist noise. When a finding has been confirmed across multiple platforms, it takes strong evidence to move it. When a finding is new and single-source, a single contradiction can shift it significantly. This mirrors how scientific confidence actually works; certainty is earned through repeated independent validation, not asserted.
Strategies transfer. Architectures don’t.
Four sessions in, the findings sort into two clean categories.
Universal findings are strategies: maximize throughput at fixed budget, regularize everything lightly, don’t remove load-bearing components. They transfer because they describe the shape of the optimization problem, not the specifics of the hardware.
Hardware-specific findings are architectural choices: RoPE base should be 200K, SwiGLU doesn’t work, 512-dim is optimal. These are artifacts of a particular GPU’s memory bandwidth, attention implementation, and compute-to-memory ratio. They only looked universal because early experiments all ran on the same hardware.
The graph tracks this distinction structurally. You don’t have to manually diff four Discussion threads. The certainty landscape shows you where robust findings climb, fragile findings drop, and CONTRADICTS links mark the boundaries.
3,300 forks are the opportunity
Here’s the thing that excites me.
Karpathy’s repo has 3,300+ forks running on everything from datacenter H100s to MacBooks to consumer RTX 3080s to Jetson boards. Each fork is an independent experiment on a different platform. Each fork is also an island.
The macOS fork might discover that Metal’s attention path changes everything about window patterns. The Windows RTX fork might discover that 10GB VRAM forces a completely different width-depth tradeoff. The Jetson fork might find that edge constraints reshape the optimization landscape in ways nobody predicted.
Right now, none of them know what the others found.
The pod is the connective layer. Each fork connects to the same shared graph. When a Mac run confirms batch halving, certainty rises for the whole community. When it finds that RoPE base 25K works better than 200K, that surfaces as a hardware-specific claim linked to the H100 finding with appropriate certainty adjustments.
3,300 forks running in isolation is 3,300 siloed experiment logs. 3,300 forks feeding one graph is a research community.
This is what the Nervous Machine frameworkdoes
The unit of collaboration isn’t a commit or a Discussion post. It’s a causal vector with a certainty score of roughly 1KB encoding of what was learned, how confident we are, and where gaps persist. That’s what travels between nodes in a network. The code, the data, the compute logs stay local. The finding propagates.
The same protocol works for any domain where distributed agents generate local observations that need to aggregate into shared knowledge without a central authority. ML experiments on GPUs. Robots learning to walk on different surfaces. Sensors in environments that diverge from simulation. The math is the same. The learning dynamics are the same. The certainty scoring is the same.
This is the protocol i’ve been building toward that helps any distributed community aggregate value from its edges. Autoresearch is the proof of concept. The forks are the distributed network. The pod is the nervous system that connects them.
Communities create enormous value at their edges. The problem has never been generating insights, it’s been aggregating them without centralizing control. That’s the gap. That’s where we live.
Try it
The autoresearch graph prior is live and open. Any MCP-compatible agent can connect, read the current certainty landscape, and contribute findings from new runs.
Full instructions: SKILL.md
Karpathy autoresearch repo: Karpathy/autoresearch
Beta to spin up your own use case: Nervous Machine Beta
We chose the mean. 3,300 agents are discovering that the edges are where the real findings live
.