How Uncertainty Evolved Around A 9-Qubit Cluster
Discriminating tests revealed a bipartite, event-bounded structure, and forced the framework to grow new primitives.

*Follow-on to “60 Days on `ibm_fez`” (Apr 21, 2026).
Framework property as thesis
The previous article closed with the 9-qubit cluster sitting at Z = 0.529 after 60 days of validation. The framework refused to keep raising its certainty. The phrase from that piece [no signal, no update] sounds like a feature description, but it is the structural behavior of the system, and the subject of this article.
The η(Z) update rule is structurally biased away from movement when evidence is the wrong shape for the hypothesis being tested. A low-certainty hypothesis at Z ≈ 0.25 updates eagerly; η ≈ 0.92, so a single corroboration meaningfully shifts certainty. A high-certainty hypothesis at Z ≈ 0.85 updates barely; η ≈ 0.03, so a single new observation contributes a few thousandths. Between those regimes sits a third state the previous article left open; moderately certain hypotheses that won’t move despite many observations. That state is informative. Confidence that won’t rise despite evidence accumulation is the framework’s way of saying: the hypothesis I am being asked to validate doesn’t fit what I am actually seeing. The averaged evidence is moderate; the structure underneath is something else.
This article describes what happened when we ran the discriminating tests the framework had been waiting for. Two readings of the cluster collapsed; one survived in modified form; the mechanism was localized to a specific subsystem; and the framework’s representation had to grow to hold what the data actually showed.
The case study, briefly
Nine qubits on ibm_fez: Q17, Q24, Q36, Q52, Q53, Q55, Q61, Q73, Q91. Thirty-six pairwise readout-error correlations across the observation window. Mean |r| = 0.46, signed mean ≈ 0 showed strong positive and strong negative correlations coexisting in the same cluster, the push-pull signature that flagged the cluster for follow-up. After 76 days of validation, the cluster’s aggregate Z had reached 0.589 across roughly 50 updates. Other inner-loop clusters built on single-mechanism shared-readout-resonator hypotheses (Q22 ↔ Q136, Q58 ↔ Q109) had reached Z ≈ 0.79 in comparable update counts. Same cadence, same η(Z) loop, very different rates of convergence.
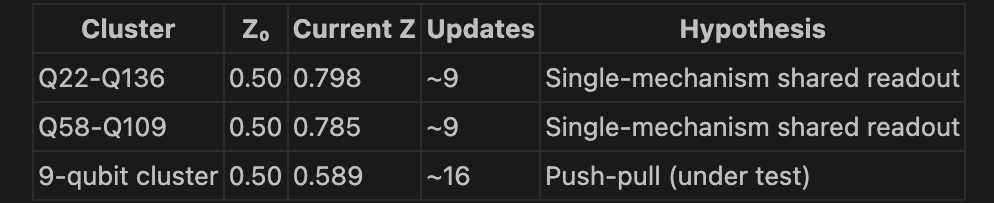
The four tests
Test 1: Spectral algorithmic partition
Spectral clustering on the 9-qubit correlation matrix recovered the manual partition exactly. Manual A {Q36, Q52, Q53, Q55, Q73} = Spectral A. Manual B {Q17, Q24, Q61, Q91} = Spectral B. The bipartite score reached 1.793 [the sum of within-block coherence (within_A = +0.626, within_B = +0.344) penalized by within-block coherence’s negation between blocks (between_AB = –0.411)]. The reading that the partition was an artifact of how the discovery engine selects correlations cannot survive a method-independent recovery of the same partition. Two methods agree because the structure is in the data.
Null distribution from 500 random subsets
Five hundred random 9-qubit subsets sampled from the chip’s 156 qubits. For each, the same bipartite-score computation. Null mean: 0.277. Null standard deviation: 0.111. Null 99th percentile: 0.616. The empirical score of 1.793 sits roughly 13.6 standard deviations above the null mean. Not one of the 500 sampled subsets reached it. p < 0.0001. The structure is wildly improbable under the null. The bipartite signature is not the kind of pattern any nine arbitrary qubits would produce by chance.
Leave-one-out stability
Each of the nine cluster members was dropped in turn; the remaining eight were re-partitioned spectrally. All nine runs preserved the same A/B grouping. The result is structurally robust, not driven by a single outlier whose removal would collapse the partition. Q17, despite being the cluster member with the most extreme readout-error trajectory, is not the qubit holding the result together. Its sub-block stays coherent without it; its cross-partition anti-correlation persists.
Sliding-window temporal signature
Twenty-two sliding 15-day windows across the analysis period. The bipartite-score trajectory was decisive. Score range: –0.265 (April 20) to +1.030 (March 15). Sharp ascent: March 6 → March 9 (0.498 → 0.886). Plateau March 9–18 at 0.88–1.03. Sharp collapse March 18 → March 21 (1.009 → 0.458, Δ = –0.551 in three days). Dormant since. The bipartite structure is not a chronic 76-day state. It is a 12-day event with sharp onset and sharper offset. The averaged-window evidence had been computed against a hypothesis (chronic single-mechanism) that didn’t match what the chip actually did.
The mechanism is metric-specific
The bipartite structure isn’t uniform across error metrics. It is sharply localized to one of them.
Readout correlations are structured. Within sub-block A, Q52_RO ↔ Q73_RO at +0.80, Q53_RO ↔ Q73_RO at +0.79, Q36_RO ↔ Q52_RO at +0.68. Group A’s readout errors move together strongly enough that any pair within the group meets the discovery threshold. Across the partition, Q73_RO ↔ Q61_RO at –0.65, Q53_RO ↔ Q91_RO at –0.63, Q53_RO ↔ Q24_RO at –0.58. Anti-correlation across the partition is comparable in magnitude to positive correlation within each side. The bipartite signature is unambiguous in the readout sub-block of the 18×18 cross-correlation matrix.
T1 correlations, on the same nine qubits, across the same window, are silent. Across-qubit T1 cross-correlations sit within ±0.20, no structural pattern, no bipartite signature, no within-block coherence. The matrix’s T1 sub-block is essentially noise.
The contrast rules out a class of mechanisms. Thermal coupling — shared dilution-fridge stages, the heuristic fridge_zone hypotheses the discovery layer seeded, anything that affects coherence times — would couple T1 across the cluster. T1 doesn’t couple. The mechanism isn’t thermal.
The mechanism is localized to the readout chain: multiplexing budget, amplifier gain allocation, frequency assignments, discriminator parameters. That is exactly where IBM’s calibration optimizer operates. The optimizer trades off readout discrimination across the multiplex; it does not trade off qubit coherence. The metric-specificity tightens the surviving reading: calibration fallout, event-bounded, mediated through the readout electronics chain.
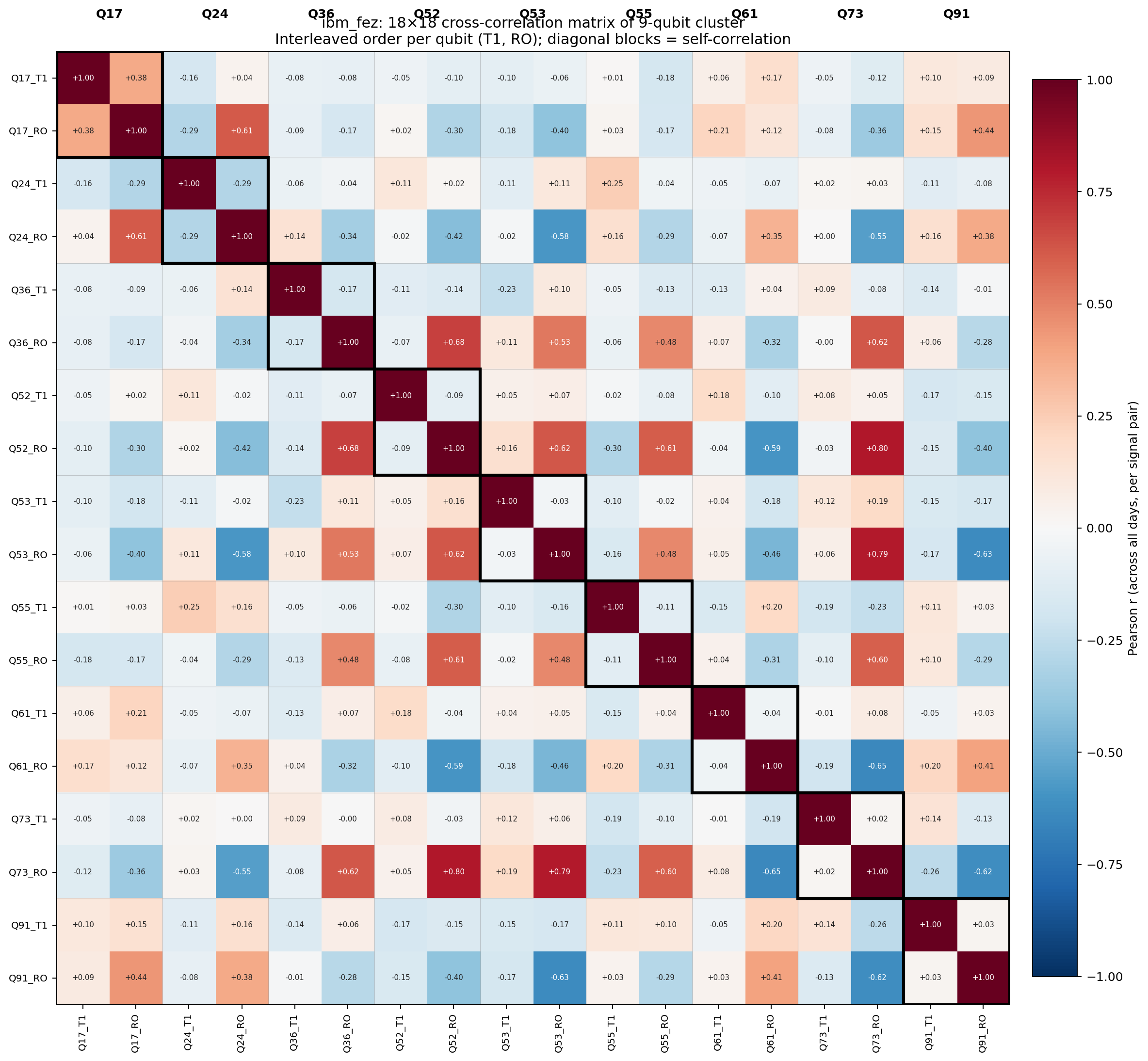
The reading that survives
Three readings of the cluster were on the table going into this analysis:
Independent drift: Coincident processes that overlapped in time without sharing a mechanism.
Selection effect: The discovery engine chose qubits whose drift anti-correlated by construction.
Calibration fallout: Group A was calibrated, displacing some shared resource that affected Group B.
Tests 1 and 2 kill Reading 2. Method-independent partition recovery and 13.6σ-significance against the chip’s null distribution rule out an artifact of the discovery engine. Test 4 kills Reading 1: independent drift produces random-walk-like sliding scores, not sharp three-day-window onset and offset transitions. Reading 3 survives, and Section 4 frames it: event-bounded fallout mediated through the readout electronics chain. A discrete intervention around March 7 ± 2, a discrete relaxation around March 19 ± 2, dormant since.
The slightly negative post-event scores, down to –0.265 in late-window slices, suggest something stronger if real. Group A and Group B may now be weakly co-correlated, opposite of the event period. That would be the structural fingerprint of a shared resource being normally shared now and reallocated during the event.
What the framework learned to represent
The previous article showed the framework correctly refusing to validate the cluster without new evidence. This article shows what the new evidence forced.
The Z hadn’t risen because the framework didn’t have the right primitives to represent what was actually happening. Three pieces of architectural growth fall out of this case study.
Events as bounded intervals. The framework had been treating the cluster as a chronic property of the chip. The sliding-window analysis revealed a 12-day window with sharp onset and offset, surrounded by dormancy. Hypotheses about chip behavior need to be representable as bounded events, not just persistent states. The η(Z) loop’s “no signal, no update” behavior was correct precisely because the chronic-state hypothesis kept failing to find current corroborating signal. The framework had no slot in its representation to say “this was a discrete event, completed.”
Composite clusters with signed children. A single cluster can decompose into sub-blocks that share a parent topology hypothesis with opposite-sign coupling. The parent is the shared resource; the children couple to it with positive and negative effects. The framework had nodes for clusters and nodes for shared-resource hypotheses, but no representation for one resource, two sign-opposed children. A finite-budget calibration optimizer that improves one group at the cost of another is the canonical case for this primitive. So is a shared LO whose reallocation lifts some qubits’ readout fidelity by lowering others’.
Sliding-window coherence as standing capability. The bipartite-score time series that revealed the 12-day event had to be computed by hand for this article. For the framework to surface this kind of structure on its own, the time-series computation needs to be standing capability [automatic for any cluster whose Z has stalled despite evidence accumulation]. The stall is the trigger; the discriminating tests are the response.
Now for the part that gives the architectural growth its full weight. IBM no longer publishes pulse-level topology metadata for Heron-class devices. Calibration logs are not externally accessible at the granularity that would let an outside observer confirm the March 7 and March 19 boundaries directly. What the framework holds about ibm_fez is therefore an inferred picture, not a verified one. It is built from observable telemetry, adjudicated by discriminating tests, and held at the certainty the evidence supports.
That posture of generating structural hypotheses from behavior alone, with the η(Z) loop holding discipline on what counts as confirmation, is the project’s response to a system that has become more opaque, not less. The architectural primitives the cluster forced are what makes that inference accountable rather than speculative.
An η(Z) loop that holds discipline on certainty produces a different kind of learning than a Bayesian update mill. When confidence stalls despite evidence, the stall is itself a signal that the representation is wrong, not the parameter values. The framework’s job in that moment is not to keep updating numbers against an ill-fitting hypothesis. It is to surface the stall, generate discriminating tests, and let new structure enter the graph. This is the essence of how the framework drives discovery.
What’s next
Cross-backend backfills on ibm_marrakesh and ibm_torino are queued. Whether the bipartite-fallout signature is ibm_fez-specific or characteristic of Heron-architecture devices is the question they answer; results will appear in the next piece.
Readers of my prior work across causal learning for thermospheric drivers and agentic belief adaptation will recognize the generalizing pattern: external uncertainty quantification as a driver for discovery, beyond the causal-structure prior baked into current AI models. A more formal piece on this cross-domain generalization is in progress. The findings on ibm_fez are foundational evidence for that argument.